Project 4: Parallel Programming with Machine Learning
Author: Zhen Tong 120090694@link.cuhk.edu.cn
Before Everthing
This is a project involving the C++ implementation of a neural network, specifically focusing on softmax regression and multilayer perceptron (MLP), utilizing stochastic gradient descent (SGD) training on the MNIST dataset. The project is organized into four tasks:
Task1: Sequential softmax regression implemented in C++
Task2: CUDA parallelized softmax regression using OpenACC
Task3: C++ implementation of a neural network (NN)
Task4: CUDA parallelized neural network using OpenACC
Task 1
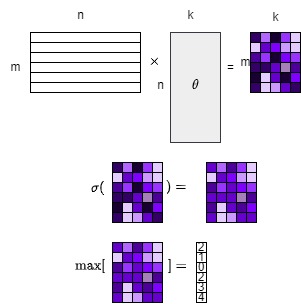
As the figure above, there is only three steps in the forward computation:
Use the matrix dot product to get the linear permutaion.
Use the softmax
get the maximum index of the softmax as the output.
Because we are doing the classification work, the loss is still the entropy loss. As for the training and parameter update, follow the fomula:
In the sequential implementation, to enhance program speed, attention should be directed toward optimizing locality. When the size of the last dimension, specifically the second dimension of the second matrix, is unknown, a general form can be employed. Two key strategies involve precomputing the pointer in advance for efficient data retrieval and reordering the sequence of nested loops to maximize data locality for a row in a matrix.
for(size_t i = 0; i < m; i ++){ auto A_row = A + i*n; // compute the pointer ahead of time, and repeatedly use auto C_row = C + i*k; for(size_t l = 0; l < n; l++){ auto B_row = B + l*k; float A_il = A_row[l]; for(size_t j = 0; j < k; j++){ // change the for loop sequence for locality C_row[j] += A_il*B_row[j]; } }}For matrix that need to first transpose than multiply, we directly multiply them leveraging the locality according to one principle: inner loop locality serve first. For example:
xxxxxxxxxxfor(size_t x = 0; x < n; x++){ auto A_row = A + x*m; auto B_row = B + x*k; for(size_t i = 0; i < m; i++){ auto C_row = C + i*k; for(size_t j = 0; j < k; ++j){ C_row[j] += A_row[i] * B_row[j]; } }}And for
If the last dimension is known, such as having 10 categories for the matrix
xxxxxxxxxxfor(size_t i = 0; i < m; i ++){ auto A_row = A + i*n; auto C_row = C + i*k; for(size_t l = 0; l < n; l++){ auto B_row = B + l*k; float A_il = A_row[l]; C_row[0] += A_il*B_row[0]; C_row[1] += A_il*B_row[1]; C_row[2] += A_il*B_row[2]; C_row[3] += A_il*B_row[3]; C_row[4] += A_il*B_row[4]; C_row[5] += A_il*B_row[5]; C_row[6] += A_il*B_row[6]; C_row[7] += A_il*B_row[7]; C_row[8] += A_il*B_row[8]; C_row[9] += A_il*B_row[9]; }}Task 2
In OpenACC, we transfer data to the GPU by using #pragma acc enter data copyin(). This pragma is employed to allocate memory on the GPU and initialize it with the specified data. We need to try to avoid unnessory copyin() operation, because cpu gpu communication is expensive.
xxxxxxxxxx Following that, we can employ parallel data computation by initially stating #pragma acc data present() and subsequently adding #pragma acc parallel loop independent. It's noteworthy that matrix multiplication necessitates the use of reduction to aggregate the results.
xxxxxxxxxxfor(size_t i = 0; i < m; i++){ for(size_t l = 0; l < k; l++){ size_t j = 0; float sum = 0.0f; // use reduction here for(; j < n; j ++){ sum += A[i*n+j] * B[j*k+l]; } C[i*k+l] = sum; }}After using all the data we need to use #pragma acc exit data delete() to free the memory on the gpu.
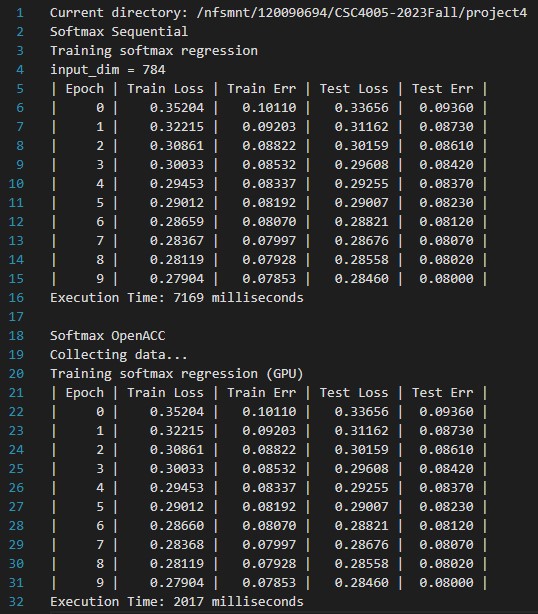
The output of the CPU and GPU openacc on nvidia tuling is as follows. However, the speed of task2 can be faster according to the baseline.
Task 3
The core concept of neural net is applying learnable linear transform and non-linear transform on the input data. The non-linear we use in this project is
Because we are still doing the classification work, the loss is still the entropy loss.
As mentioned above the
xxxxxxxxxxfor(int i = 0; i < m; i++){ auto A_row = A + i*n; auto C_row = C + i*k; for(int x = 0; x < k; x++){ auto B_row = B + x*n; for(int j = 0; j < n; j++){ C_row[x] += A_row[j] * B_row[j]; } }}Task 4
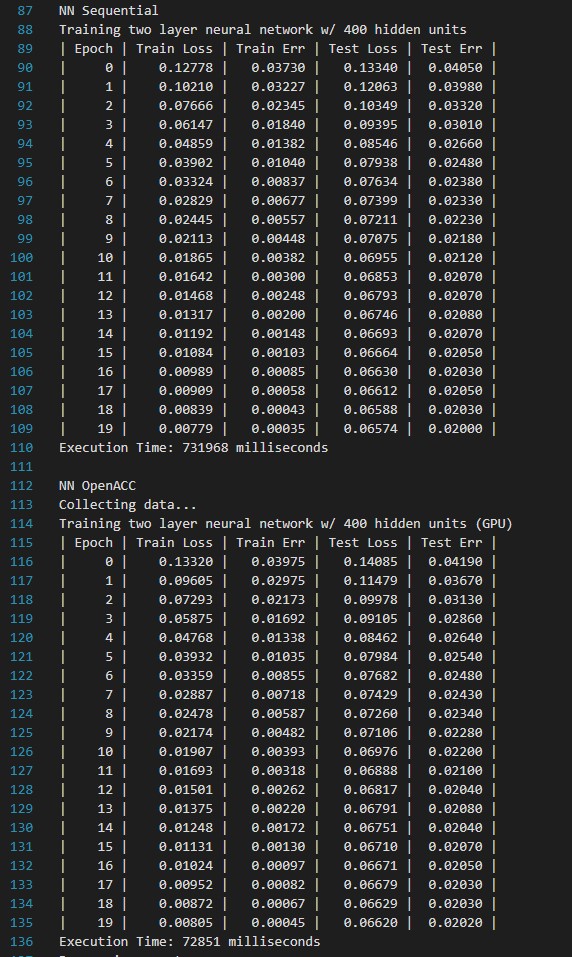
Utimlize the openacc to speedup the nn training. We follow the less CPU-GPU data transition principle again. Because of the SGD and floating-point precision, the loss and err during training can be slightly different.
Performance
| #(params) | Seq:softmax(784) | OpenACC:softmax(784) | Seq:NN(317,600) | Seq:NN(317,600) |
|---|---|---|---|---|
| Time(ms) | 7169 | 2017 | 731968 | 72851 |
The number of parameter of softmax is
| softmax | NN | |
|---|---|---|
| Speedup | 355.43% | 10047.47% |
Profiling OpenACC with nsys for Task 2
CUDA API Summary:
cuStreamSynchronize: Represents 68.7% of the total time spent on GPU operations.
cuLaunchKernel: Accounts for 28.4% of the total time, indicating kernel execution.
cuMemHostAlloc, cuMemAlloc_v2, cuMemAllocHost_v2, cuModuleLoadDataEx, cuMemcpyDtoHAsync_v2, cuMemcpyHtoDAsync_v2, cuMemsetD32Async, cuEventRecord, cuEventSynchronize, cuStreamCreate, cuEventCreate: Contribute to smaller percentages, representing various memory operations and CUDA API calls.
GPU Kernel Summary:
matrix_dot_trans_openacc: Takes up 63.8% of the GPU kernel time, involving matrix transposition and multiplication.
matrix_dot_openacc, matrix_softmax_normalize_openacc, matrix_minus_openacc, matrix_set_zero, matrix_mul_scalar_openacc: Contribute to the remaining GPU kernel time with specific matrix operations.
GPU Memory Transfer Summary:
[CUDA memcpy HtoD]: Consumes 99.6% of the total time, indicating high data transfer from the host to the device.
[CUDA memcpy DtoH], [CUDA memset]: Contribute to a smaller percentage of time, representing data transfer from the device to the host and memory set operations.
GPU Memory Size Summary:
Memory operations primarily involve [CUDA memcpy HtoD], and the average memory size is 10,087.567 bytes.
OS Runtime Summary:
poll, pthread_cond_timedwait, ioctl, read, mmap64, sem_timedwait, fopen64, fclose: These system calls contribute significantly to the overall runtime.
pollis particularly notable, representing 54.7% of the time.
Profiling OpenACC with nsys for Task 4
Here is the analysis of the provided report in the specified format:
CUDA API Summary:
| Time(%) | Total Time (ns) | Num Calls | Average | Minimum | Maximum | StdDev | Name |
|---|---|---|---|---|---|---|---|
| 98.0 | 68,196,909,108 | 216,461 | 315,054.0 | 713 | 649,018,594 | 6,234,591.1 | cuStreamSynchronize |
| 2.0 | 1,368,962,408 | 216,360 | 6,327.2 | 3,843 | 6,350,763 | 14,415.3 | cuLaunchKernel |
| ... | ... | ... | ... | ... | ... | ... | ... |
GPU Kernel Summary:
| Name | Time(%) | Total Time (ns) | Instances | Average | Minimum | Maximum | StdDev |
|---|---|---|---|---|---|---|---|
| matrix_dot_trans_openacc_34_gpu | 54.5 | 37,103,407,971 | 24,000 | 1,545,975.3 | 32,512 | 5,489,037 | 1,514,046.1 |
| matrix_dot_openacc_14_gpu | 39.1 | 26,641,504,435 | 24,080 | 1,106,374.8 | 9,696 | 649,013,563 | 18,557,523.1 |
GPU Memory Transfer Summary:
| Operation | Time(%) | Total Time (ns) | Operations | Average | Minimum | Maximum | StdDev |
|---|---|---|---|---|---|---|---|
| [CUDA memcpy HtoD] | 99.6 | 34,530,320 | 167 | 206,768.4 | 896 | 1,375,484 | 425,223.9 |
| [CUDA memcpy DtoH] | 0.2 | 78,782 | 80 | 984.8 | 864 | 1,568 | 149.1 |
GPU Memory Size Summary:
| Operation | Total | Operations | Average | Minimum | Maximum | StdDev |
|---|---|---|---|---|---|---|
| [CUDA memcpy HtoD] | 408,933.984 | 167 | 2,448.706 | 3.906 | 16,384.000 | 5,095.396 |
| [CUDA memcpy DtoH] | 0.313 | 80 | 0.004 | 0.004 | 0.004 | 0.000 |
OS Runtime Summary:
| Name | Time(%) | Total Time (ns) | Num Calls | Average | Minimum | Maximum | StdDev |
|---|---|---|---|---|---|---|---|
| poll | 50.1 | 72,827,685,292 | 739 | 98,548,965.2 | 10,649 | 100,825,159 | 12,287,789.5 |
| pthread_cond_timedwait | 49.8 | 72,516,307,726 | 145 | 500,112,467.1 | 499,824,488 | 500,264,410 | 31,418.3 |
The provided analysis includes summaries for CUDA API, GPU Kernels, GPU Memory Transfer, GPU Memory Size, and OS Runtime.
Compile and Execute
Compile the cpp (openacc) using the bash program, and the runtime output will be recored in the Project4-Results.txt
xxxxxxxxxx$ ./test.shThe test.sh bash code contains sbatch that you can run it yourself alone:
xxxxxxxxxx$ sbatch sbatch.shView the perfromance of task2 softmax openacc, and store the output in the report1.txt
xxxxxxxxxx$ nsys stats profiling/report1.qdrep > profiling/report1.txtView the performance of task 4 nn openacc, and store the output in the report2.txt
xxxxxxxxxx$ nsys stats profiling/report2.qdrep > profiling/report2.txtReference
CUHKSZ Project Description: https://github.com/tonyyxliu/CSC4005-2023Fall/tree/main/project4
CMU Code: https://github.com/hanquanjushi/10-714/blob/main/hw0/src/simple_ml_ext.cpp