DIMES: A Differentiable Meta Solver for Combinatorial Optimization Problems
Zhen Tong Dec-20-2023
Introduction
Here is the corrected version:
This paper is written by Ruizhong Qiu from UIUC, and Zhiqing Sun∗, Yiming Yang from CMU Language Technologies Institute. The paper has been accepted by NeurIPS 2022.
This research focuses on the scalable problem in Graph Combinatorial Problems. Because Deep RL suffers from the costly decoding of COP solutions, the model encounters the sparse reward problem when dealing with large graphs. You can understand this by considering the construction of the graph or improving the graph to the final state as a very long trajectory because the graph is very large, and it only receives the reward at the end of the graph. Therefore, the reward is very sparse with respect to the long trajectory.
The researchers introduced a compact continuous space to parameterize the underlying distribution of candidate solutions, allowing massively parallel on-policy sampling without the costly decoding process. This effectively reduces the variance of the gradients by the REINFORCE algorithm. They also use meta-learning as an initialization of the model parameters.
DIMES can be generalized to problems, including locally decomposable combinatorial optimization problems, such as the Maximal Independent Set (MIS) problem for synthetic graphs and graphs reduced from satisfiability (SAT) problems.
Details
The novelty of DIMES compared to other construction heuristics learners is:
- Unlike previous methods which generate the solutions via a constructive Markov decision process (MDP) with rather costly decoding steps (adding one un-visited node per step to a partial solution), we introduce a compact continuous space to parameterize the underlying distribution of discrete candidate solutions and to allow efficient sampling from that distribution without costly neural network-involved decoding.
- Use meta-learning to train.
DIMES uses improving heuristics and unsupervised reinforcement learning.
Now we define the problem formally:
is the set of all the solutions, is one solution, stands for an instance, is the function for the solution cost. The solution space of COP is discrete, for example, the path of TSP, or the combination of MIS. However in the paper they parameterize the solution space with a continuous and differentiable vector , where denotes the variables in the problem instances , for example, edges in TSP and nodes in MIS, and estimates the probability of each feasible solution as:
where is an energy function over the discrete feasible solution space, is a -dimensional vector with element indicating whether the variable is included in feasible solution , and the higher value of means a higher probability for the variable produced by
Now the target function is the expectation over the continuous solution distribution for
According to the REINFORCE-based update rule:
Nevertheless, a common practice to sample from the energy pθ functions
requires
MCMC(energy-based learning), which is not efficient enough. Hence we propose to design an auxiliary distribution qθ over the feasible solutions Fs, such that the following conditions hold: 1) sampling from is efficient, and 2) and should converge to the same optimal . Then, we can replace with in our objective function. is the baseline.
Auxiliary Distribution For TSP
Only having a vector for the solution is not enough to describe the TSP solution. we need to add another distribution to describe the path. Because the TSP path is a ring, that can start from any point. Therefore
Given the start node , we factorize the probability via chain rule in the visiting order:
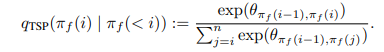
Auxiliary Distribution For MIS
In the MIS problem, the solution is a set, but our sample is a vector, therefore we need to use a distribution to describe it.
is an ordering of the independent nodes in solution , and is the set of all possible orderings of the nodes in .
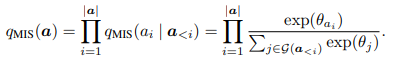
Meta-Learning
They train the GNN using the Meta-Learning conception. The idea is simple, select some graph instances and view them as tasks, and sample solutions for the graphs, after collecting many samples with gradients update the parameter for GNN

is the parameter for the GNN, is the input features for a graph instance in the collection , si the adjacent matrix of the graph,
The meta-learning updates is:
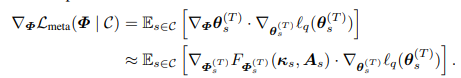
Performance